
Một trong những điều chúng ta quan tâm khi lập trình Multi-thread là các luồng data và các threads chia sẻ dữ liệu như thế nào để tránh race data mà vẫn đảm bảo hiệu suất của chương trình.
False sharing, có lẽ ít bạn quan tâm đến vấn đề này nhưng nó lại ảnh đáng kể đến performance trong một chương trình C++. Và trong bài này, mình sẽ giải thích False sharing là gì, nó ảnh hưởng như thế nào đến các chương trình C++ và các kỹ thuật để giảm thiểu, giúp tăng hiệu suất chương trình.
Đặt vấn đề
False sharing có thể làm giảm hiệu suất. Nó xảy ra khi hai luồng sử dụng một số dữ liệu khác nhau (ở đây là dữ liệu khác nhau nên không hề có race data nha các bạn) nhưng chúng không được chia sẻ một cách hợp lý giữa threads dẫn đến chúng lại nằm trong cùng Cache line nếu hai luồng đang thực thi trên các cores khác nhau và liên tục cập nhật biến nằm trên cùng một cache line.
Nghe chỗ này hơi khó hiểu phải không? Hãy cùng mình tìm hiểu kĩ hơn nhé
Giải thích
Trước tiên các bạn cần hiểu Cache line là gì?
Để hiểu một cách đơn giản thì thông thường các caches như L1, L2 của Processor thường không truy cập hay xử lý ở các vị trí bộ nhớ riêng lẻ theo byte như các biến mà một chương trình vẫn hay khai báo; thay vào đó chúng xử lý theo các memory-blocks được gọi là Cache line. Các khối bộ nhớ này thường là 32 hoặc 64 bytes nó sẽ phụ thuộc vào processor.. Bởi vì cache hardware chỉ xử lý các cache-line-sized có kích thước bằng cache line, nên các dữ liệu nhỏ ở các vị trí bộ nhớ lân cận sẽ nằm trong cùng một cache line.
Vậy False sharing liên quan gì đến Cache line và nó ảnh hưởng như nào đến hiệu năng? Hãy quan sát hình bên dưới nhé (hình ảnh mình lấy từ internet)

Giả sử bạn có 2 threads:
Thread 0: xử lý biến thứ nhất có size = 1
Thread 1: xử lý biến thứ hai cũng có size = 1
Về bản chất hai biến này không liên quan gì đến nhau đúng không nào? Nên các bạn nghĩ chúng sẽ không ảnh hưởng gì đến hiệu năng.
Nhưng không, vì hai biến này có size nhỏ hơn size của cache line ( ở đây mình ví dụ cache-line-size = 64 bytes nhé), vậy nên 2 biến sẽ được lưu trên cùng một cache line
Vậy theo lý thuyết về cache line ở trên điều gì sẽ xảy ra? Chắc các bạn cũng đoán được đúng không. Hai threads này sẽ bị down performance khi chúng cùng truy cập và xử lý đến một cache line tại cùng một thời điểm và đương nhiên sẻ ảnh hưởng đến performance của chương trình rồi đúng không?
Hãy cùng mình kiểm chứng lý thuyết trên nhé.
Hãy benchmark đoạn code này nhé:
#include <iostream>
#include <vector>
#include <thread>
#include <atomic>
#include <chrono>
constexpr int ALIGNMENT = 4;
struct alignas(ALIGNMENT) AlignedData {
AlignedData() { val = 0; }
int val;
};
int main() {
srand((unsigned int)time(NULL));
AlignedData aligned_data0{};
AlignedData aligned_data1{};
std::cout << "Address of aligned_data0 : " << &aligned_data0 << '\n';
std::cout << "Address of aligned_data1: " << &aligned_data1 << '\n';
std::cout << "Size block - "
<< (unsigned long long) & aligned_data1
- (unsigned long long) & aligned_data0 << '\n';
// create lambda function for computing
auto worker = [](AlignedData& d) {
const int count = 10000000;
for (int i = 0; i < count; ++i) {
d.val = (i + i) / 2 + rand();;
}
};
// benchmark
std::vector<std::thread> threads;
auto start = std::chrono::high_resolution_clock::now();
auto t0 = std::thread([&]() { worker(aligned_data0); });
auto t1 = std::thread([&]() { worker(aligned_data1); });
t0.join();
t1.join();
auto stop = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(stop - start);
std::cout << "spent time: " << duration.count() << "ms \n";
}
Thoạt đầu nhìn vào đoạn code trên các bạn sẽ không thấy vấn đề gì đúng không? Vì 2 thread truy cập đến hai biến hoàn toàn khác nhau nên không thể xảy ra race data được.
Nhưng chúng ta hãy benchmark với 2 trường hợp là False sharing và True sharing xem kết quả ra sao nhé! Đầu tiên hãy check cache line của máy mình là bao nhiêu bằng cách:
$getconf LEVEL1_DCACHE_LINESIZE
hoặc
$cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
Như máy của mình là 64 bytes nhé.
- Trường hợp 1 – False sharing: Chúng ta sẽ set constexpr int ALIGNMENT = 4; và chạy thử nhé, kết quả sẽ như sau:

Chúng ta có 2 biến aligned_data0 và aligned_data1 có size = 4, mà cache line của mình là 64 bytes, vậy chúng sẽ được sắp xếp như sau:
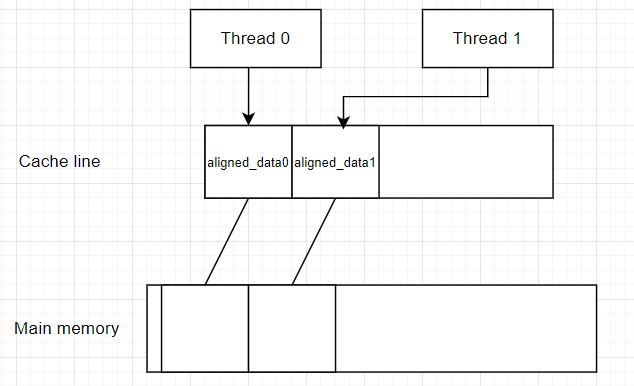
Như cách bạn thấy, chúng sẽ được nằm trên cùng 1 cache line, và 2 thread cùng truy cập đồng thời đến cache line này nên sẽ bị down performance => spent time = 176ms
- Trường hợp 2 – True sharing: Chúng ta sẽ constexpr int ALIGNMENT = 64; đúng bằng cache line size của mình nhé, chạy lại nào:
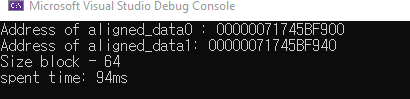
Wow, tốc độ đã tăng đáng kể đúng không, như chúng ta thấy 2 biến được aligned với size=64, lúc này chúng sẽ được sắp xếp như sau:
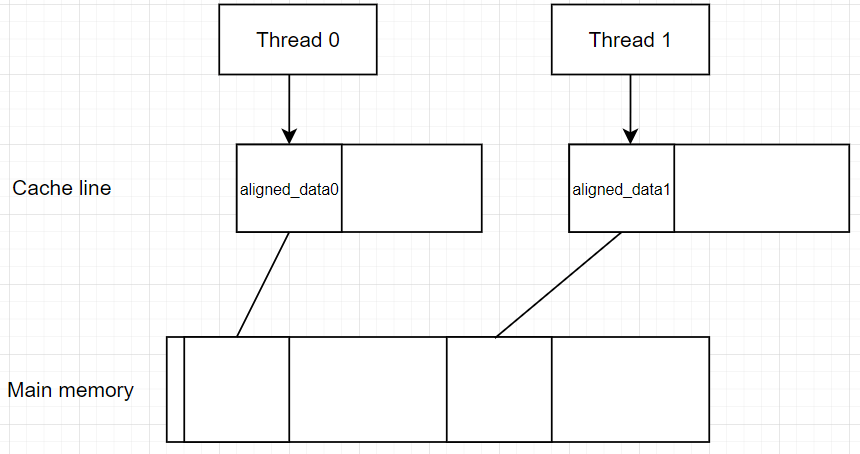
Như các bạn đã thấy, vì size của chúng bằng size của cach line nên chúng sẽ nằm trên 2 cache line khác nhau, nên sẽ không bị tranh chấp giữa hai threads như ở trường hợp False sharing => tăng performance => spent time = 94 (nhanh gần gấp đôi)
Đến đây chắc các bạn đã hiểu False sharing là gì và nó ảnh hưởng đến tốc độ chương trình như thế nào rồi đúng không.
Các cách tránh False Sharing
- Tránh ghi vào dữ liệu chung được truy cập từ nhiều threads.
- Căn chỉnh dữ liệu chung được chia sẻ theo độ lớn của cache line.
- Khi khi lập trình song song hóa một thuật toán, dữ liệu phân vùng sẽ được đặt dọc theo các cache line chứ không phải trên cùng cache line
Kết luận
Như vậy trong bài viết này mình đã đã trình bày về hiện tượng False Sharing khi lập trình multi-thread, nguyên nhân, sự ảnh hưởng của nó đến hiệu năng của chương trình như thế nào, và cách để tránh. Hi vọng bài viết hữu ích cho các bạn, nếu các bạn thấy bài viết hay thì hãy cho chia sẻ cho các anh em lập trình khác cùng biết nhé. Cám ơn các bạn đã ghé đọc ^^.

Bình luận về bài viết này