
Không chỉ riêng với C++ cũng như tất cả các ngôn ngữ khác, map và hashmap là hai containers được sử dụng rất phổ biến, giải quyết được rất nhiều bài toán một cách dễ dàng. Nhưng không phải ai cũng hiểu và sử dụng một cách hợp lý.
Trong bài bài viết này mình sẽ chỉ ra sự khác biệt lớn giữa map vs hashmap, điểm mạnh, điểm yếu, benchmark để so sánh và lưu ý khi sử dụng.
Map là gì?
std::maplà một associative container có key được sắp xếp theo các cặp key-value với các key là duy nhất.- Các key được sắp xếp dựa dựa vào predicate so sánh class Compare = std::less<Key>, có thể do người dùng define, mặc định là từ bé đến lớn
- Operation: search, erase, insert đều có time complexity là logarit
- Các containers cùng kiểu với map gồm có: std::set (không chứa value, chỉ lưu key là giá trị duy nhất), std::multimap (có lưu key-value với các keys trùng nhau).
- Map được implemented theo cơ chế của Red-Black Tree, các bạn phải nhớ điều này rất quan trọng vì red-black tree là self-balancing binary search trees nên đó là lí do vì sao các operation của map luôn là Logarit (O(logn))
- Ví dụ:
#include <iostream>
#include <map>
#include <string>
int main()
{
// create
std::map<int, std::string> m{{3, "Hello"},
{1, "World"},
{2, "Haha"}};
// insert
m.insert({5, ", Bye!!!"});
// erase key
m.erase(2);
// print
for (const auto& [key, value] : m)
std::cout << '[' << key << "] = " << value << "\n";
}

Unordered_map là gì?
std::unordered_map cũng tương tụ như map, nó là một associative container có các cặp key-value, với các key là duy nhất.- Điều khác biệt là unordered_map thì các key không được sắp theo thứ tự và người cũng không thể define Compare class để sắp xếp được, vì key của unordered_map sẽ được tự động sắp xếp theo thứ tự của hash function thành các bucket (điều này mình sẽ giải thích cụ thể hơn ở phần dưới)
- unordered_map cũng có các operations như: search, erase, insert nhưng khác biệt lớn là time complexity là constant O(1) (rất khác biệt đúng không nào).
- Và điều quan trọng là unordered_map được implement theo cơ chế hash map

- Tại sao lại luôn là O(1)?
Mình lấy một ví dụ đơn giản, như các bạn thấy ở hình trên (nguồn internet), ví dụ hashmap define sẵn một table với size_table = 15 lưu các giá trị bởi index
Index được xác định với hàm băm (hash function): index = value % size_table.
Như vậy với một lần search, insert, erase một giá trị nào đó trong thấy table, ta chỉ cần sử dụng hash function để băm ra index tương ứng rồi nhảy đến index là xong. Vì vậy time complexity luôn là O(1). Tương tư cho những kiểu key phức tạp hơn, ta sẽ có table và hash function tương ứng để băm ra key phù hợp
- Cùng kiểu với unordered_map còn có: unordered_set, unordered_multimap
- Ví dụ:
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
// create
std::unordered_map<std::string, std::string> u =
{
{"RED", "#FF0000"},
{"GREEN", "#00FF00"},
{"BLUE", "#0000FF"}
};
// insert
u.insert({"WHITE","#FFFFF"});
u["WHITE"] = "#FFFFFF";
// erase
u.erase("RED");
for (const auto& [key, value] : u)
std::cout << key << ": " << value << std::endl;
}

Sự khác nhau
| Attributes | Map | Unordered Map | |
| Order key | Yes | No | |
| Implementation | Red-Black Tree | Hashmap | |
| Time Complexity | Search | O(logn) | O(1) |
| Insert | O(logn) | O(1) | |
| Erase | O(logn) | O(1) | |
| Headers | <map> | <unordered_map> | |
Benchmark
- Code benchmark, các bạn có thể benchmark online đoạn code dưới tại link: Quick C++ Benchmarks (quick-bench.com)
#include <cstdlib>
#include <map>
#include <unordered_map>
#include <vector>
#include <iostream>
constexpr int num_items{128};
template <typename map_type>
void build_map(map_type &map, std::vector<int> const& vals) {
for (int i = 0; i < num_items; i++)
map[i] = vals[i];
}
template <typename map_type>
void probe_map(map_type &map, std::vector<int> const &indices,
std::vector<int> &vals) {
for (int i = 0; i < num_items; i++)
vals[i] = map[indices[i]];
}
void ordered_map_test(benchmark::State& state) {
std::vector<int> indices(num_items);
std::vector<int> vals(num_items);
srand(0);
for (int i = 0; i < num_items; i++) {
indices[i] = rand() % num_items;
vals[i] = rand();
}
std::map<int, int> map;
for (auto _ : state) {
build_map(map, vals);
probe_map(map, indices, vals);
}
}
BENCHMARK(ordered_map_test);
void unordered_map_test(benchmark::State& state) {
std::vector<int> indices(num_items);
std::vector<int> vals(num_items);
srand(0);
for (int i = 0; i < num_items; i++) {
indices[i] = rand() % num_items;
vals[i] = rand();
}
std::unordered_map<int, int> map;
for (auto _ : state) {
build_map(map, vals);
probe_map(map, indices, vals);
}
}
BENCHMARK(unordered_map_test);
- Data size = 16, với số lượng data ít thì map sẽ nhanh hơn với độ phức tạp là Logarit ở dữ liệu nhỏ là không đáng kể, và map cũng sử dụng ít vùng nhớ hơn, không phải chạy hash function
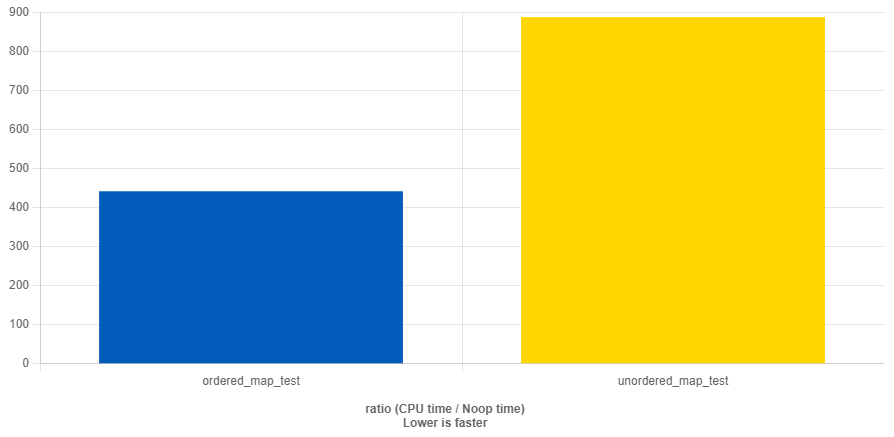
- Data size = 128: Bắt đầu có sự khác biệt khi tăng size

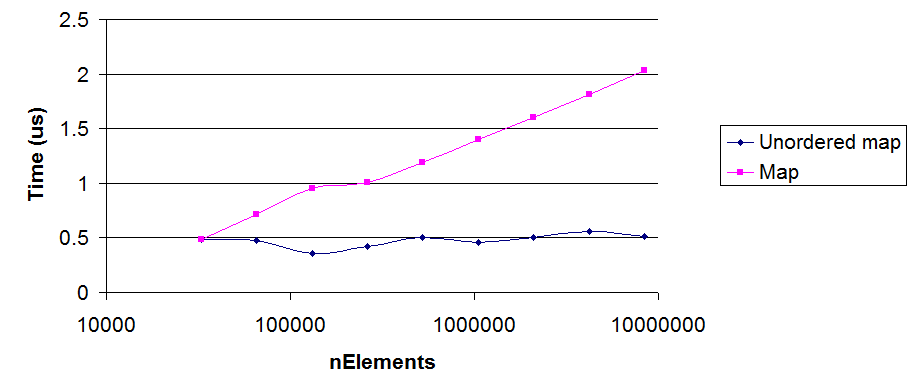
- Data size lớn: > 2M: unordered_map thể hiện sự vượt trội về performance với lượng data lớn.
Kết luận
- Map:
- Sử dụng cho những trường hợp cần sắp xếp các keys
- Với lượng dữ liệu nhỏ <100 thì nên sử dụng map vì sẽ tốn ít vùng nhớ hơn, không phải chạy hash function, hiệu năng tốt hơn
- Unordered_map (hashmap):
- Sử dụng cho những tường hợp không cần sắp xếp keys
- Khi lưu trữ dữ liệu lớn tầm vài K trở lên thì unordered_map là sự lựa chọn tối ưu
Như vậy trong bài viết này mình đã giới thiệu cho các bạn về map và hashmap (unordered_map), hi vọng các hiểu rõ và áp dụng hiệu quả trong khi lập trình ứng dụng cũng như lập trình thi đấu vì nó ảnh hưởng khá lớn đến hiệu năng của chương trình.
Hi vọng bài viết hữu ích cho các bạn, nếu các bạn thấy bài viết hay thì hãy chia sẻ cho các anh em lập trình khác cùng biết nhé. Cám ơn các bạn đã ghé đọc ^^. Chúc các bạn làm việc hiệu quả ^^

Bình luận về bài viết này